過去の自分がpipenvを使っていたことをようやく思い出したので、やっとpythonコードが書けるようになりました!!
歌った時に音程のチェックができるプログラムを書きたい
カラオケの採点モードみたいなプログラムを作るのが最終目標です!
(raspberrypiに実装して上手く歌えていたらランプ点灯みたいにしたいなあ)
まずは録音するためのpyaudio、音声ファイルを作成するためのwave
brew install pyaudio
pipenv install pyaudio
pipenvインストールで早速引っかかる。
Creating a virtualenv for this project...
~ 中略 ~
Installing pyaudio...
Error: An error occurred while installing pyaudio!
よし、pipenvはあきらめてpip使おう。
buto@LisanoMacBook-Air ~ % pip install pyaudio
Collecting pyaudio
Downloading PyAudio-0.2.11.tar.gz (37 kB)
Could not build wheels for pyaudio, since package 'wheel' is not installed.
Installing collected packages: pyaudio
Running setup.py install for pyaudio ... done
Successfully installed pyaudio-0.2.11
WARNING: You are using pip version 20.1; however, version 21.3.1 is available.
You should consider upgrading via the '/Users/buto/.pyenv/versions/3.8.2/bin/python3.8 -m pip install --upgrade pip' command.
warning出てるけどまあいっか笑 waveも同様にpipでインストールしました
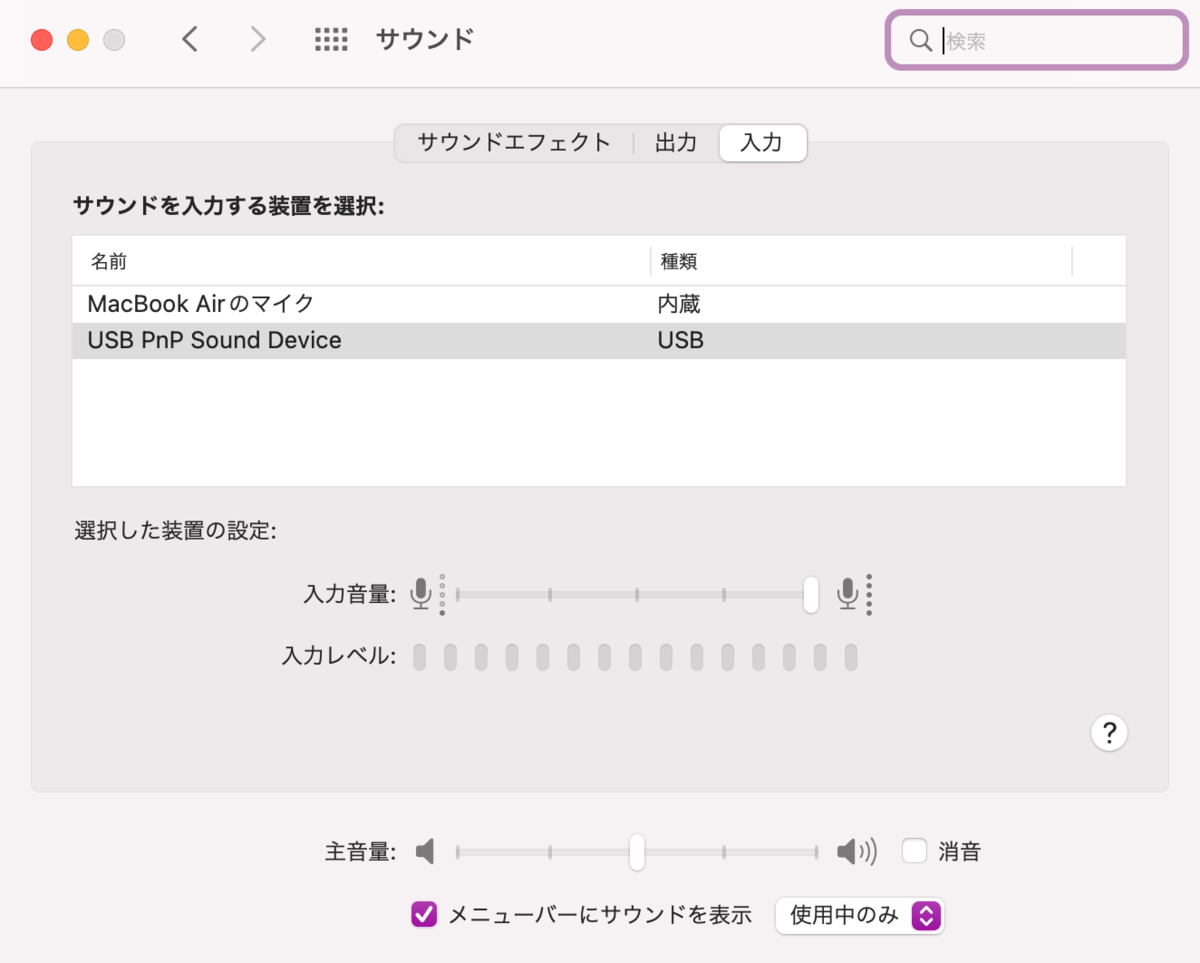
マイクの設定
私は600円ほどのUSBマイクを買いました(Amazonでは売り切れている人気商品!)
共立プロダクツ MI-305 [USBマイク]
今日はraspberrypiではなくMacBookで試してみるのでマイクをPC内蔵からUSBに切り替えます
マイクで録音してwavファイルを作成する
Python3で録音してwavファイルに書き出すプログラム
もうコピペでいいですね笑 丁寧なコメントまで書かれているので勉強にもなります
私は録音の秒数を3秒に、サンプルレートを4420Hz、ファイル名をvoice.wavに変更しました
import pyaudio
import wave
RECORD_SECONDS = 3
WAVE_OUTPUT_FILENAME = "voice.wav"
iDeviceIndex = 0
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 4420
CHUNK = 2**11
audio = pyaudio.PyAudio()
stream = audio.open(format=FORMAT, channels=CHANNELS,
rate=RATE, input=True,
input_device_index = iDeviceIndex,
frames_per_buffer=CHUNK)
print ("recording...")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print ("finished recording")
stream.stop_stream()
stream.close()
audio.terminate()
waveFile = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
waveFile.setnchannels(CHANNELS)
waveFile.setsampwidth(audio.get_sample_size(FORMAT))
waveFile.setframerate(RATE)
waveFile.writeframes(b''.join(frames))
waveFile.close()
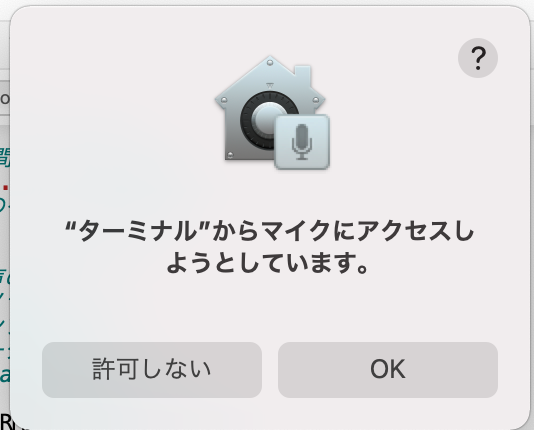
このコードを実行すると初回は以下のダイアログが出るのでマイクへのアクセスを許可します
recording...と標準出力に表示されてから3秒録音され、pyファイルと同じディレクトリにvoice.wavが作成されました!

ちなみにCHANNELS=2にするとステレオモードになるそうです 私はマイク1個なのでモノラルでいいですね
今さら聞けないステレオとモノラルの違い
余談ですがpyaudioで録音するサンプルコードでは44.1kHzが多かったので調べてみるとCDで使われている周波数だそうです
サンプリング周波数選択のポイント
442Hzでチューニングして歌うと10倍以上の4420Hz以上が録音に適したサンプリング周波数となるのかな??
